认识 DolphinScheduler
你总是会需要定时执行各种类型的任务,这些任务之间还可能存在着各种依赖关系。面对这样的问题别说做了,单是想想都觉得脑壳疼。
这个场景在数据开发领域十分的常见,那么怎么才能很好的解决这些个问题呢?本文则为大家介绍一个工作流任务调度开源系统——DolphinScheduler。
什么是DolphinScheduler
Apache DolphinScheduler是一个分布式易扩展的可视化DAG工作流任务调度开源系统,旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。

DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。
DolphinScheduler的特性
简单易用
- 可视化DAG
用户友好的,通过拖拽定义工作流的,运行时控制工具
- 模块化操作
模块化有助于轻松定制和维护
丰富的使用场景
- 支持多种任务类型
支持Shell、MR、Spark、SQL等10余种任务类型,支持跨语言,易于扩展
- 丰富的工作流操作
工作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数
高可靠性
去中心化设计,确保稳定性。 原生 HA 任务队列支持,提供过载容错能力。 DolphinScheduler 能提供高度稳健的环境。
高扩展性
支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行。
DolphinScheduler部署方式
支持四种部署方式:
- 单机部署
仅适用于 DolphinScheduler 的快速体验
- 伪集群部署
在单台机器部署 DolphinScheduler 服务,该模式下 master、worker、api server 都在同一台机器上
- 集群部署
在多台机器部署 DolphinScheduler 服务,用于运行大量任务情况。
- Kubernetes部署
在 Kubernetes 集群中部署 DolphinScheduler 服务,能调度大量任务,可用于在生产中部署。
对于刚接触DolphinScheduler的同学,推荐使用单机部署的方式快速体验。
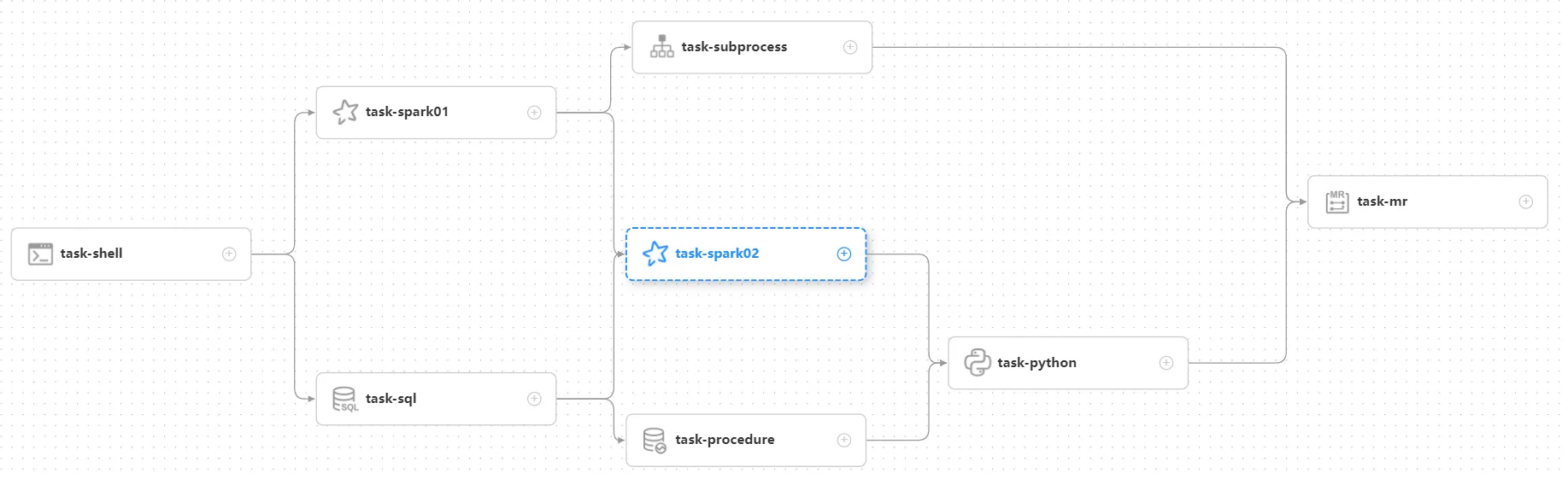
进阶
如果有任务调度需求的场景,可以尝试使用DolphinScheduler。丰富的任务类型可以满足我们实际场景下复杂的逻辑。如果你想要进一步了解DolphinScheduler,可以关注:遇码,回复ds获取官方文档。