认识DuckDB
- Github近20万Stars
- 下载次数每月达百万
- 扩展的下载流量每天超4TB
- 大小只有50MB
- 仅有18人的团队
- 诞生只有短短五年
- 即将发布第一个大版本1.0.0
这极具矛盾的数据背后就是我们今天的主角——DuckDB。
前言
早就想要写一写DuckDB了,如果非要给这个早加一个时间,我希望是五年前(那个时候DuckDB才刚刚起步)。
最初接触DuckDB只是把它当成嵌入式数据库SQLite的替代品,并且自认为SQLite经过这么多年的打磨与验证,现在就是无可替代般的存在(无知是阻碍我们进步的最大敌人)。然而当我一步步开始深入了解DuckDB的时候,我几乎是笑着完成,它完全颠覆了我对一个小小的数据库的认知。
一切都不晚,一切都刚刚好!
DuckDB是什么
DuckDB是一个快速的、in-process的OLAP数据库,底层采用列式存储。

名字的由来:创建者认为鸭子具有很强的适应能力,可以依靠任何东西生存,这与他们设想的数据库系统运行方式类似,所以被命名为DuckDB。
DuckDB的创建者们设想打造一套分析数据库,其性能与F1赛车相当,但用户友好度却向丰田卡罗拉看齐。
另外,当如今的大数据数据库都在采用分布式架构,标榜TB乃至PB级的数据处理规模时,DuckDB则站在了对立面,认为99%的用户远远达不到“大数据”的体量。
“这有个烦人的文件,我想读取他的内容并执行一些聚合操作。”不知道多少人问过这个问题。现在想想每次都把一个上百M的CSV文件上传到数仓后才能看看里面有什么是多么的笨拙。然而这样的尴尬局面都会因为DuckDB而戛然而止。
DuckDB的特点
- 免费、开源
- 嵌入式,不需要服务器,使用超级方便
- 忠于传统 SQL
- 采用列式存储(用于高效聚合)及向量化处理(用于提高性能)功能
- 具有丰富的功能集,支持完整的标准SQL、事务、二级索引
- 支持Python、R、Java、Node.js等编程语言
- 扩展机制灵活,可以直接读取CSV、JSON、Parquet等文件
- 专门针对数据分析和OLAP(在线分析处理)而设计
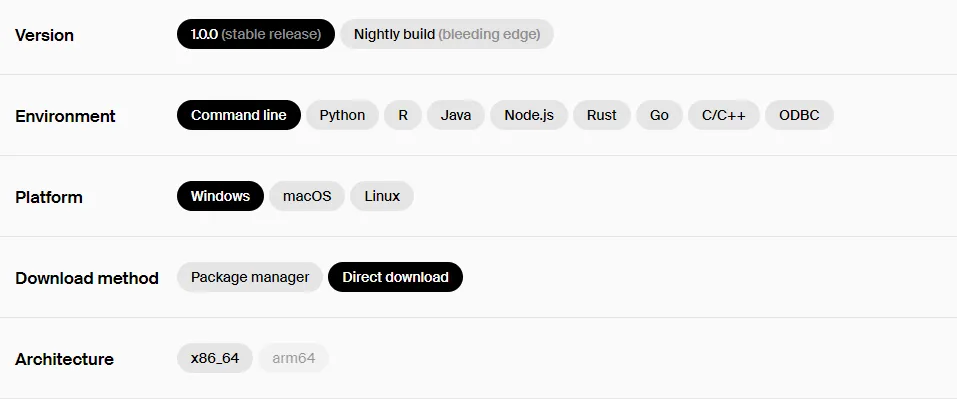
DuckDB初体验
本文采用Windows系统。
- 下载DuckDB并解压
下载地址https://github.com/duckdb/duckdb/releases/download/v1.0.0/duckdb_cli-windows-amd64.zip
解压后
- 双击启动
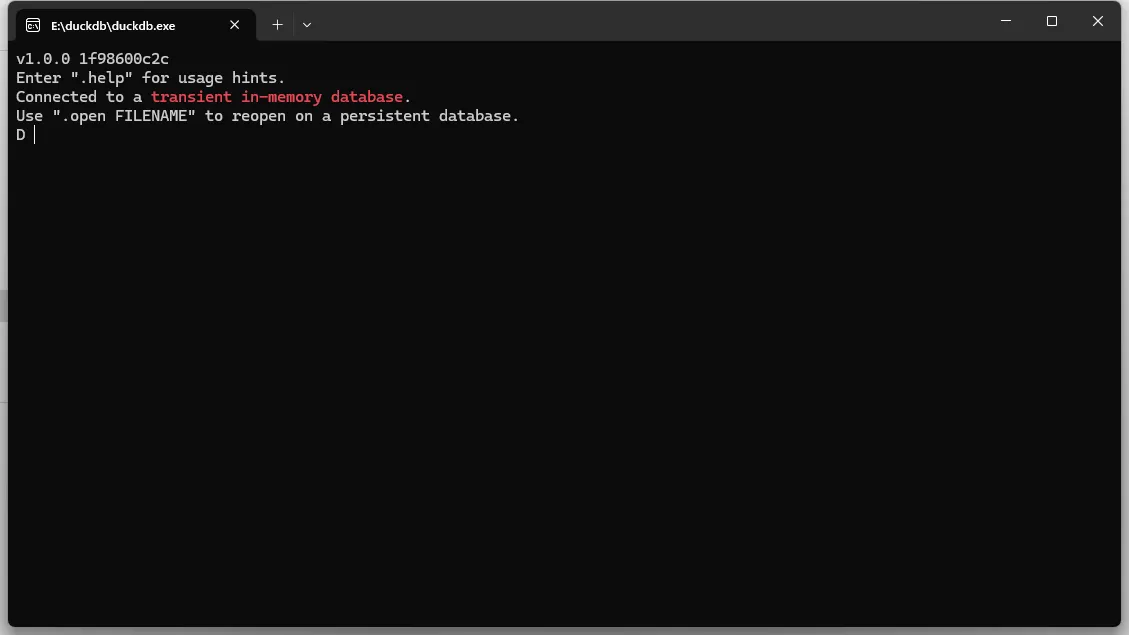
至此,你就可以使用DuckDB了。没错,你没有看错,就是这么极致的丝滑。
- 使用
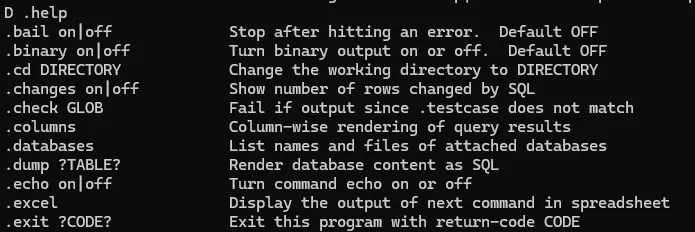
.help查看帮助命令
- 对本地CSV文件计数
63w+的数据量,只是一瞬间。
不能再演示了,我怕你激动、兴奋的跳起来。
进阶
DuckDB让你心动了吗?如果你想要学习数据分析,你不再需要学习安装Mysql,不再需要学习Python,只需要动动手,立马就可以开始。
关注:遇码,回复duckdb,获取官方文档。