五分钟玩转超人气OLAP数据库DuckDB
本文将为同学们介绍如何用数据库管理工具DBeaver玩转DuckDB。如果你对DBeaver还不了解,可以查看:
开始上手
- 启动DBeaver
- 新建数据库连接
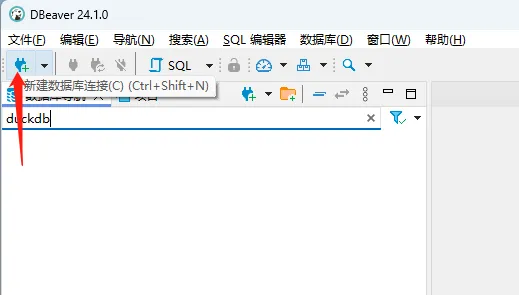
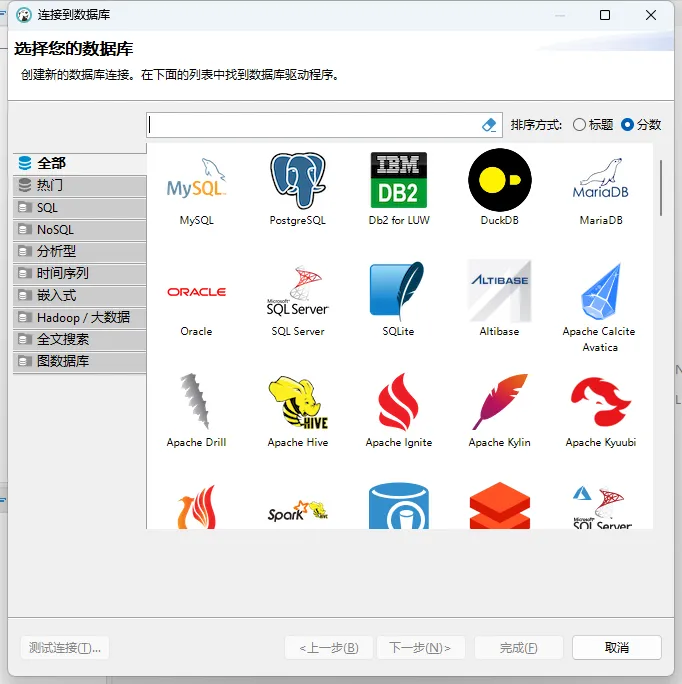
告诉大家一个小诀窍,如果同学们遇到特定场景不清楚如何做数据库选型的时候,不妨看看左侧的分类,每个分类下都罗列出了相关的数据库,我们可以挑选一些做详细调研。
- 搜索DuckDB,选择并下一步
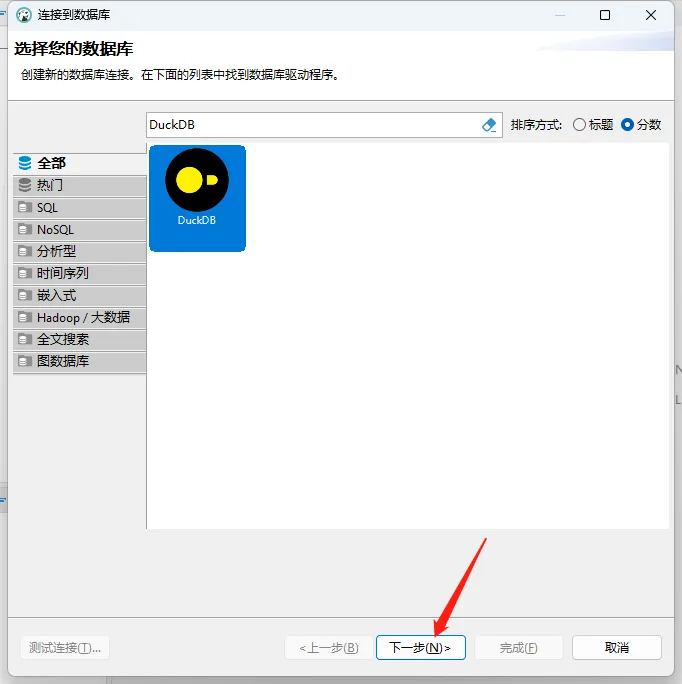
- 创建数据库文件
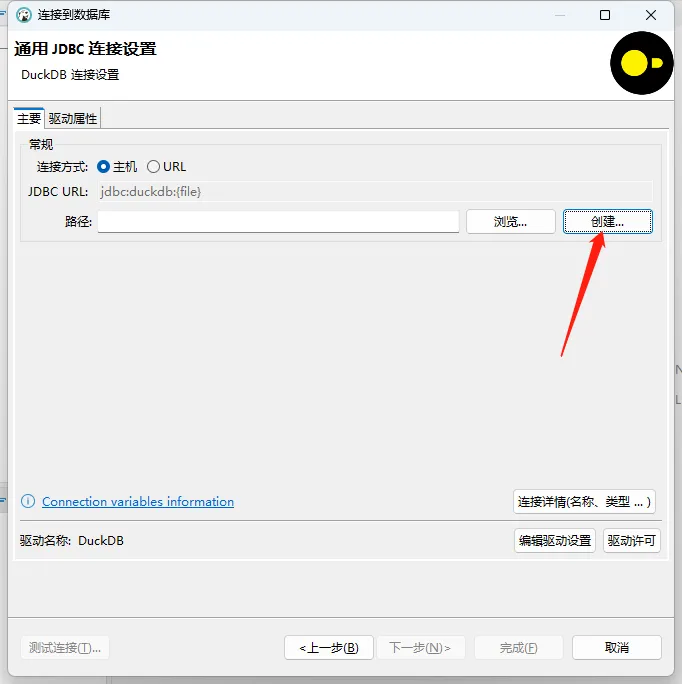
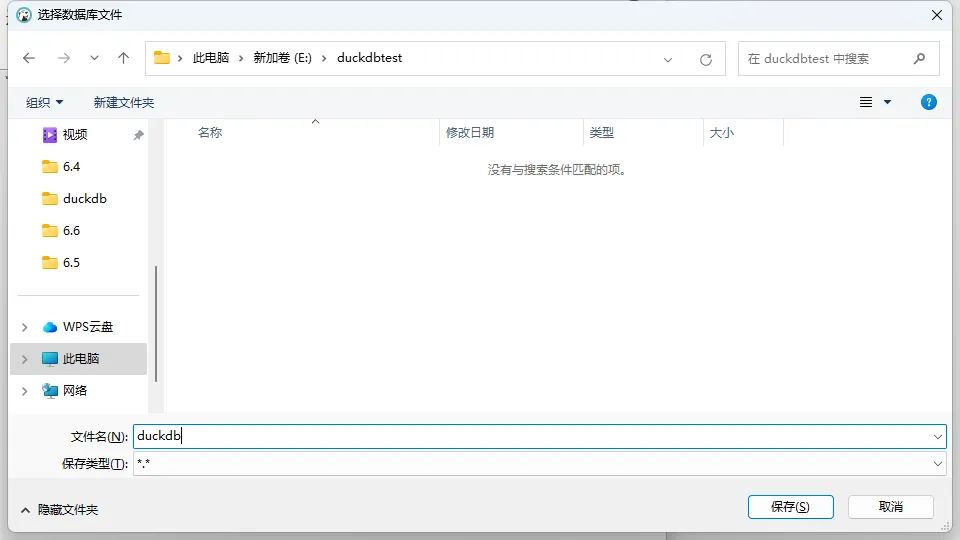
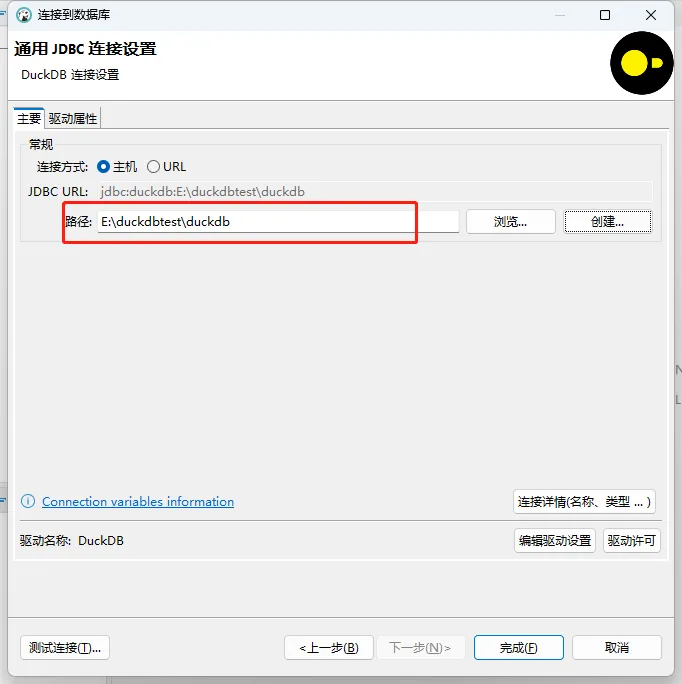
- 测试连接
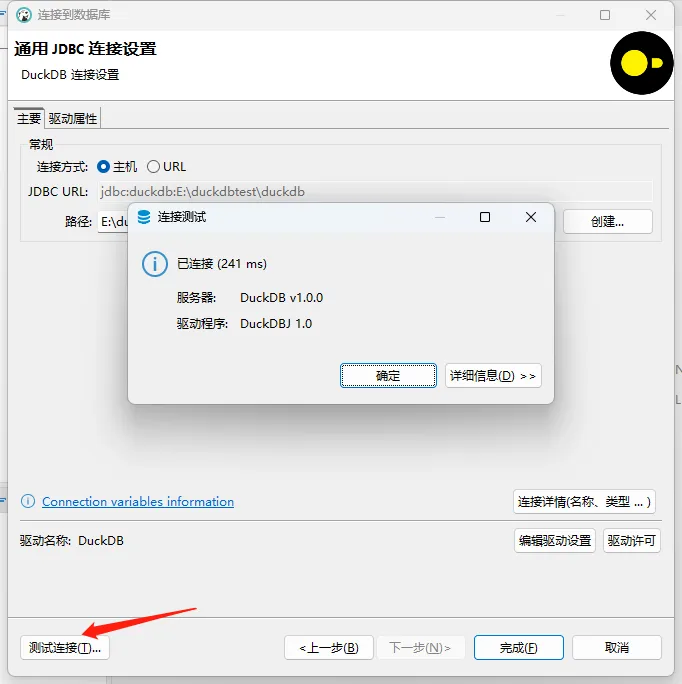
当弹出已连接,确认,点击完成,就已经可以使用DuckDB了。
- 了解DuckDB文件
我们就可以看到,我们创建的名为duckdb的数据库本质上就是一个文件。
- 新建SQL编辑器
 右击——SQL编辑器——新建SQL编辑器
右击——SQL编辑器——新建SQL编辑器
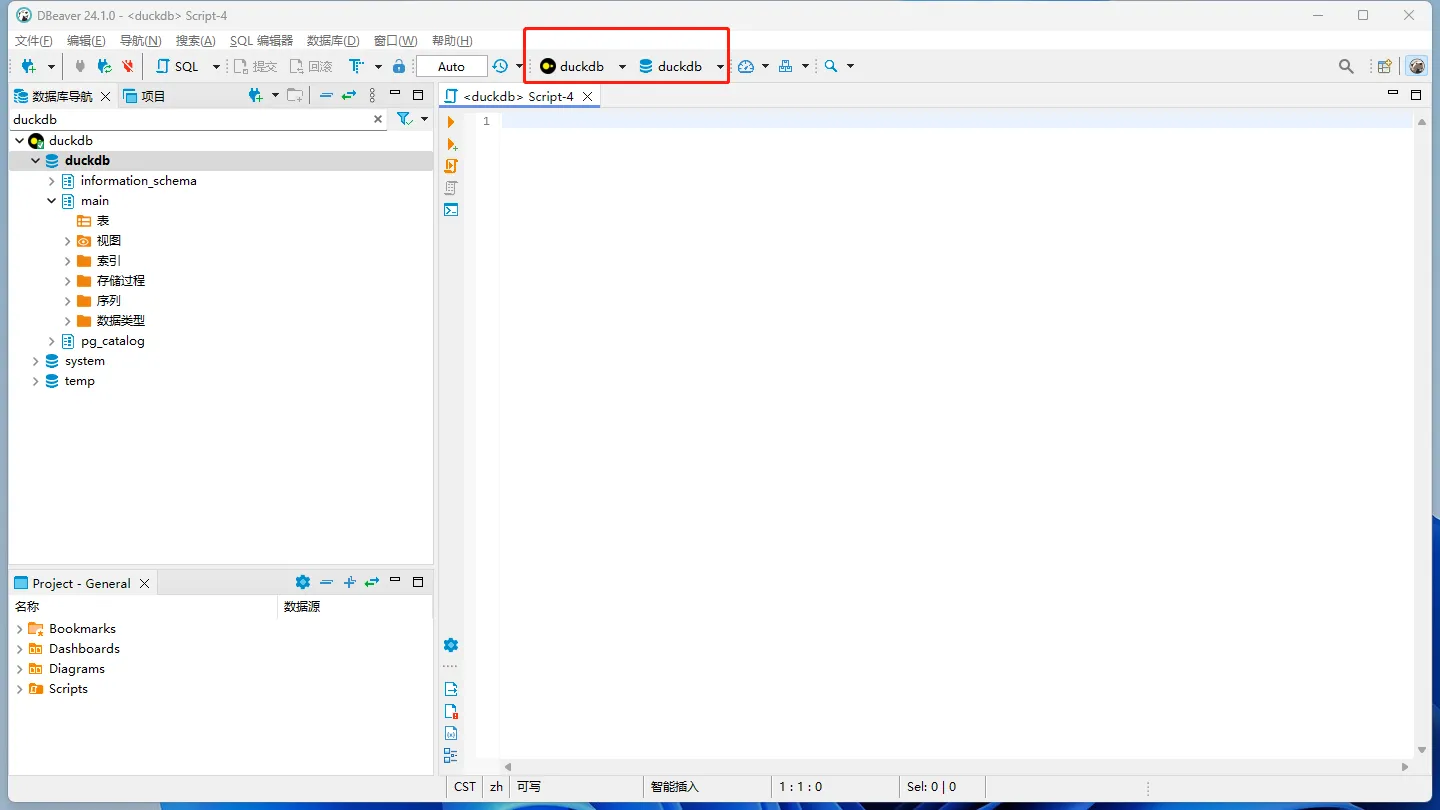
编辑器创建好以后,请确保数据库选择也是正确的(上图红框内)
- 创建第一张表
weather
sql
CREATE TABLE weather (
city VARCHAR,
temp_lo INTEGER,
temp_hi INTEGER,
prcp REAL,
date DATE
);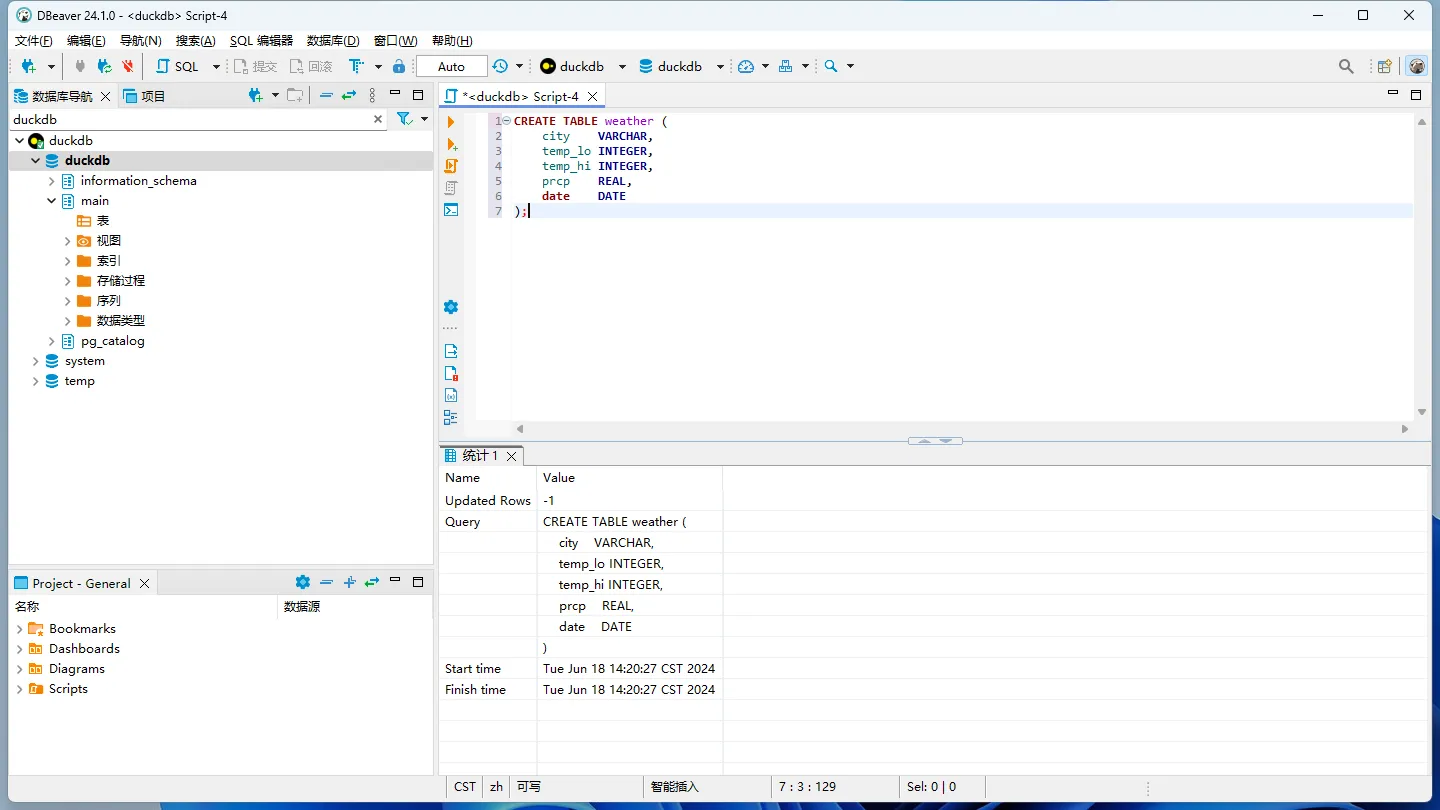
刷新后,左侧在main —— 表下已经出现weather表
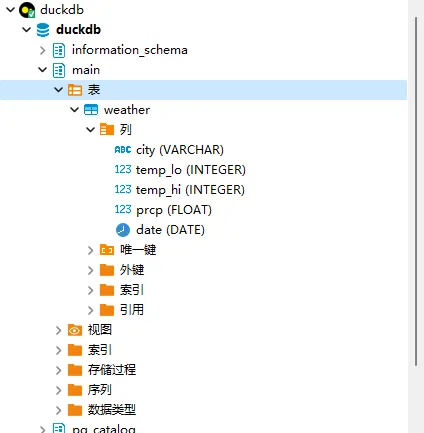
- 插入第一条数据
sql
INSERT INTO weather
VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');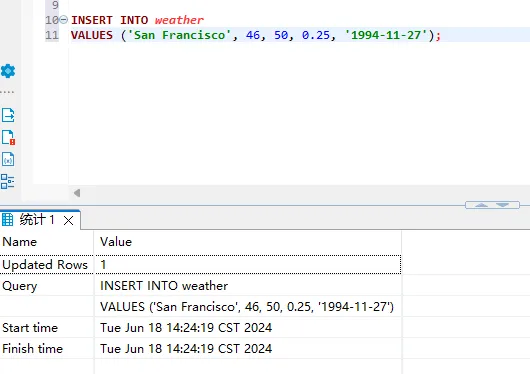
- 查询数据
sql
select * from main.weather ;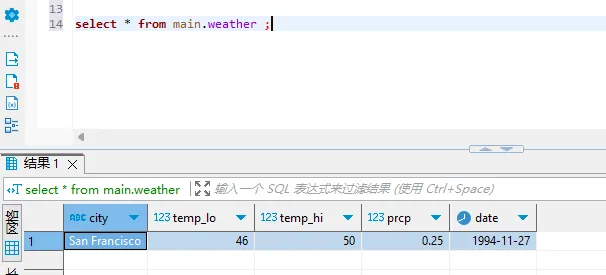
- 疯狂插入更多的数据
sql
INSERT INTO main.weather
select * from main.weather;当我把数据量变成近3亿后 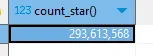
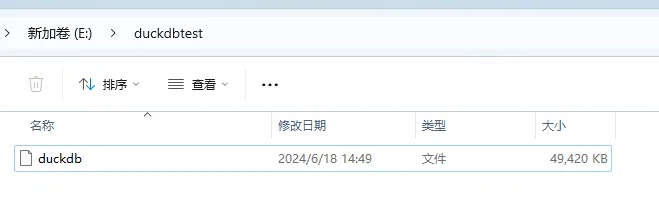
数据库文件达到了近50M
- 尝试聚合查询
求和
sql
select sum(temp_lo), sum(temp_hi) from main.weather limit 10;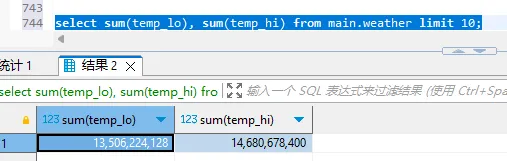
分组求和
sql
select city, sum(temp_lo), sum(temp_hi) from main.weather
group by city;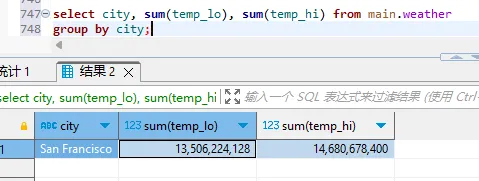
上亿数据量做聚合查询,都可以在秒级返回查询结果,这样的性能,Mysql表示压力很大。
至此,带领同学们初步体验了DucdDB变态般的非凡性能,我表示真的爱了。
进阶
本文只为同学们演示了DuckDB的基本用法,然而DuckDB更具神奇魅力的地方则在于可以直接使用外部的文件。后续将继续为同学们讲解用DuckDB如何查询外部文件数据。更多详细内容请关注:遇码,回复duckdb,获取官方文档。