DuckDB百亿级数据性能测试
前面有说过,DuckDB的创建者一开始就放弃了分布式,然后就有同学提出质疑,DuckDB会有性能瓶颈。我只想说,目前DuckDB可以说是单机场景下大数据量分析的最佳选择。
本文,我将为同学们演示DuckDB在百亿级数据量下的性能表现,我感觉我已经彻底魔怔了,百亿级数据量意味着什么?
百亿级数据是多少
我们假设一家企业每天可以产生1000万的数据量,那么产生100亿的数据量就需要1000天(超过两年半)。
我们按照前文3亿数据量,CSV文件约9GB,那么100亿就是300G。这个数据量我相信这个世界上已经没有几个单机可以处理这个CSV文件了。
此情此景,如何解决呢?
答案就是Parquet。
Parquet是什么
Parquet又称Apache Parquet,是Apache Hadoop生态系统的一种免费、开源的面向列的数据存储格式。
Parquet优点
数据压缩
列式存储
与编程语言无关
开源格式,免费使用
支持复杂数据类型
创建超百亿的数据量
- 创建数据库文件并创建表
CREATE TABLE weather (
city VARCHAR,
temp_lo INTEGER,
temp_hi INTEGER,
prcp REAL,
date DATE
);
- 插入数据
INSERT INTO main.weather
VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
- 反复插入数据,使单表数据量达到上亿级别
INSERT INTO main.weather
select * from main.weather;
重复执行SQL,单表数据量会达到上40亿级别。
数据量超40亿之后再使用该方式可能会提示内存不足,所以我们再优化一下
INSERT INTO main.weather
select * from main.weather limit 500000000;每次我们只插入5亿条数据,重复插入,知道达到超过100亿。 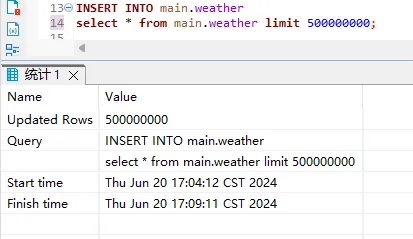
- 确认单表数据量
select count(*) from main.weather;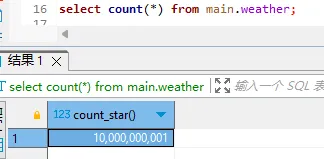
这边百亿只超过了1条,调皮一下下。
- 测试内部表查询性能
select city, count(*), sum(temp_lo), sum(temp_hi) from main.weather
group by city;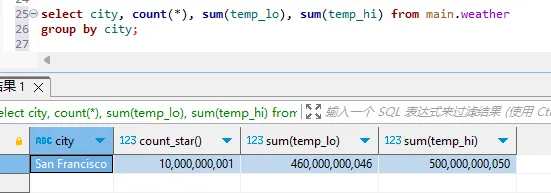
耗时约34s,你是否能接受呢。
- 导出为Parquet格式
copy main.weather to 'E:\duckdbtest\weather.parquet' (format 'parquet');由于导出时间过长,则先导出1亿数据量,然后通过复制的方式得到100份含有一亿数据量的文件。
copy (select * from main.weather limit 100000000) to 'E:\duckdbtest\weather.parquet' (format 'parquet');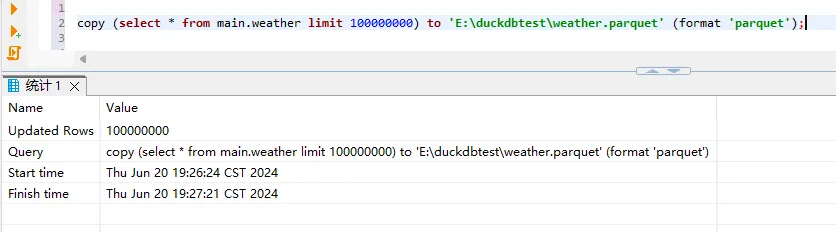
- 验证数据量
select count(*) from 'E:\duckdbtest\*.parquet';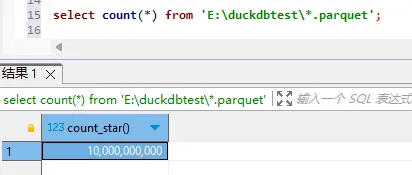 通过正则匹配的方式,可以把多个文件里的数据合并读取,这也是DuckDB更灵活的特点。
通过正则匹配的方式,可以把多个文件里的数据合并读取,这也是DuckDB更灵活的特点。
分组聚合
select city, sum(temp_lo), sum(temp_hi) from 'E:\duckdbtest\*.parquet'
group by city;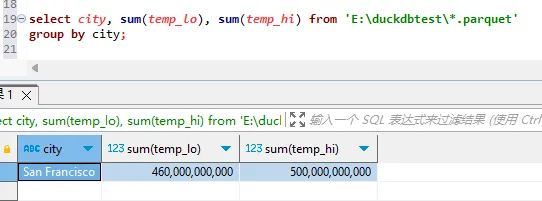
耗时约4min。
总结,Parquet相比CSV可以节省大量的存储空间,查询性能也更好,100亿数据量4min内完成聚合计算,表现还是相当可以的。但是性能最好的还是DuckDB的内部表,可以把数据读出数据后保存到内部表后再做分析。
create table weater_parquet as
select * from 'E:\duckdbtest\*.parquet';如果一次写入太慢,可以考虑分批写入。
进阶
在日常处理数据过程中,对于中间数据过程可以尝试使用占用空间更少的Parquet格式,同时Parquet文件也可以用于Hive等其它大数据产品中。针对复杂的分析需求,可以使用数仓开发的分层思维,一层层做聚合,使得开发效果达到最高。想要学习DuckDB更多玩法,请关注:遇码,回复duckdb,获取官方文档。