DuckDB玩转超亿级CSV
相信很多同学都遇到过这样的场景,有一个上百万条数据的CSV文件,然后想做一些分析。这时我们有哪些选择呢?
- 使用Excel直接打开
现在单机性能也都普遍很好了,所以对于百万级的数据量也是可行的。但是如果是千万级或者上亿级,恐怕就心有余而力不足了。
- 使用Pandas
这也确实是目前大多数人的选择,性能还可以忍受,但是需要会Python,最好还会Jupyter就更好了。
- 使用Mysql等数据库
把CSV文件的数据导入到数据库中使用,这样也是一个选择。但是数据量达到千万级就是在挑战数据库的性能了。
那么有没有一种足够足够简单并且没有性能瓶颈的方式可以来做数据分析呢?
本文将会给同学们介绍如何使用DuckDB轻松玩转超亿级的CSV。
步骤
- 创建数据库文件并创建表
sql
CREATE TABLE weather (
city VARCHAR,
temp_lo INTEGER,
temp_hi INTEGER,
prcp REAL,
date DATE
);
- 插入数据
sql
INSERT INTO main.weather
VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
- 反复插入数据,使单表数据量达到上亿级别
sql
INSERT INTO main.weather
select * from main.weather;
重复执行SQL,单表数据量会达到上亿级别。
- 确认单表数据量
sql
select count(*) from main.weather;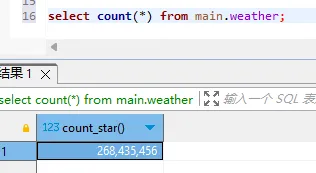
- 把weather表中的数据导出到CSV文件中
sql
copy main.weather to 'E:\duckdbtest\weather.csv' with(header, delimiter '|');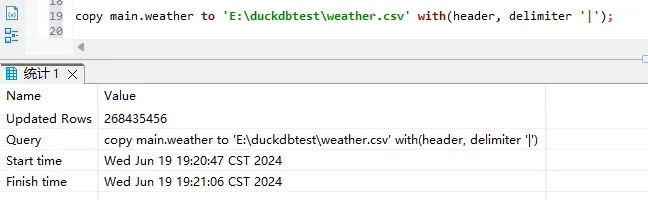
注意文件的路径,可以使用绝对路径。
此时我们就得到了一个9GB的CSV文件。
另外我们还可以选择部分数据导出到CSV中
sql
copy (select * from main.weather limit 10) to 'E:\duckdbtest\weather_10.csv' with(header, delimiter '|');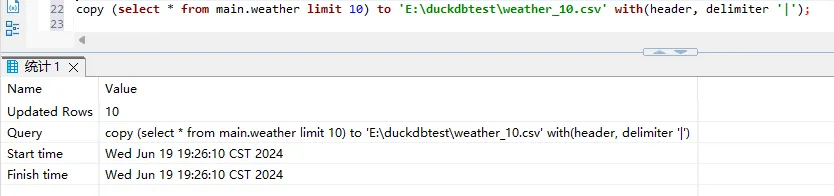

- 读取
weather.csv文件
sql
select * from 'E:\duckdbtest\weather.csv' limit 10;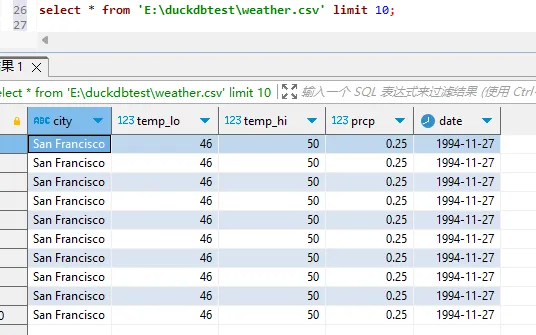
注意文件的路径,用绝对路径。
- 分组求和
sql
select city, sum(temp_lo), sum(temp_hi) from 'E:\duckdbtest\weather.csv'
group by city;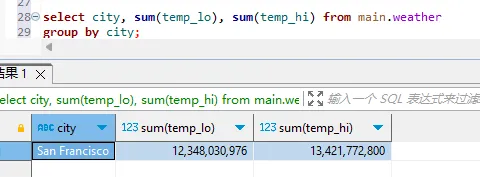
上亿的数据量,10s以内就可以返回结果。
- 模糊查询
sql
select count(*) from 'E:\duckdbtest\weather.csv'
where city like 'San%';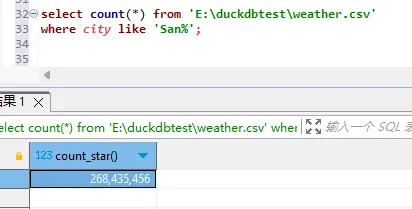
也是10s以内就可以返回结果。
- 读取CSV文件并存表
sql
create table main.weather_csv as
select * from 'E:\duckdbtest\weather.csv';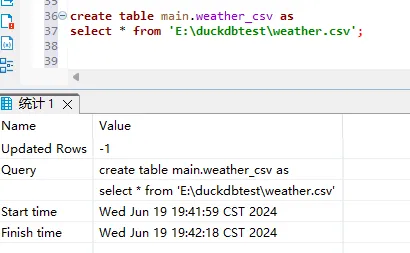
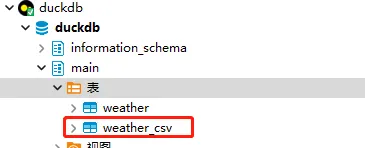
至此,就为同学们演示了如何读取CSV文件以及如何保存为CSV文件。不知道你有没有被DuckDB的性能以及灵活、自由的操作所折服。
进阶
有同学可能会说了,如果数据存放在比如S3等云端,难道每次都需要把数据下载下来才能分析吗?这就要强调一下DuckDB的扩展能力了,借助httpfs (HTTP and S3)扩展可以直接使用S3中的数据进行分析,将丝滑进行到底。更多详细用法请关注:遇码,回复duckdb,获取官方文档。