认识MTEB榜单
如今究竟是卷模型还是卷应用,真是仁者见仁智者见智,自Chatgpt引爆大模型以来,人们对于通用模型的关注就没有消停过。听说谁谁家的模型好,又听说那家的模型得第一了,用户对这类消息也是趋之若鹜,好不热闹。
那么问题来了,我们究竟应该怎么选择模型呢?本文将为大家介绍——MTEB。
MTEB是什么
MTEB(Massive Text Embedding Benchmark)是衡量文本嵌入模型(Embedding模型)的评估指标的合集,是目前业内评测文本向量模型性能的重要参考。
MTEB旨在帮助用户在多种任务中找到最佳得嵌入模型
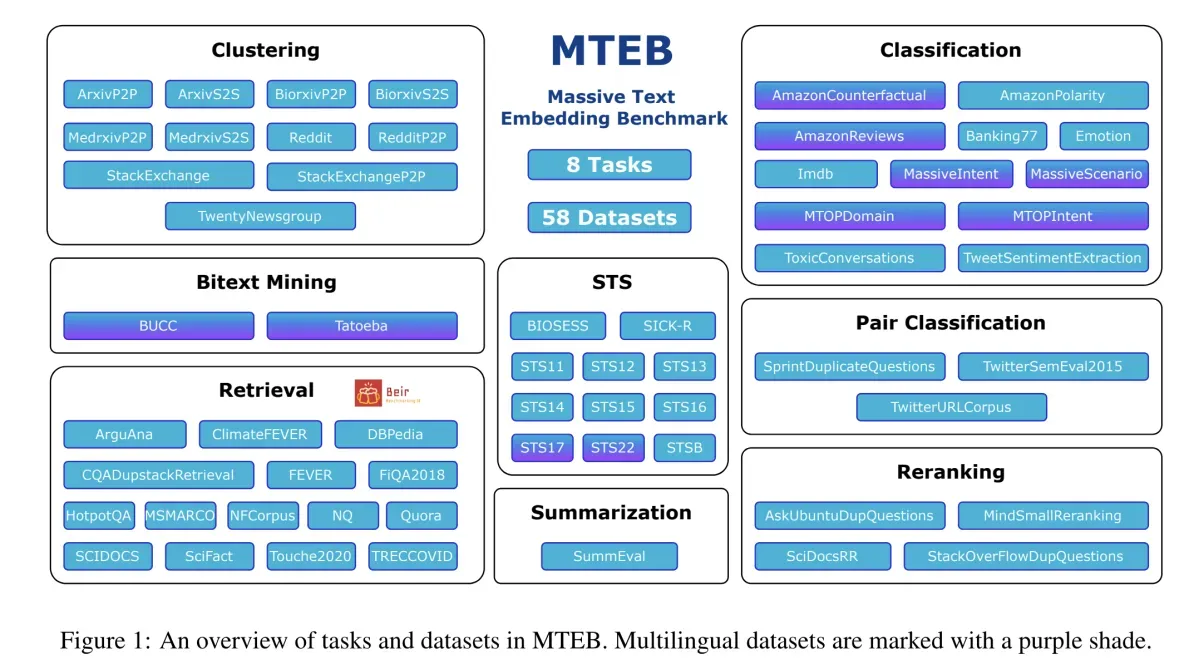
MTEB的特点
- 广泛性
MTEB包含8个任务领域的56个数据集,并在排行榜上总结了超过2000个结果
- 多语言支持
MTEB涵盖高达112种不同语言,并对多种多语言模型进行了比特挖掘、分类和语义文本相似度(STS)任务的基准测试。
- 可扩展性
无论是新增任务、数据集、评价指标还是排行榜更新,MTEB都非常欢迎任何贡献
C-MTEB
C-MTEB(Chinese Massive Text Embedding Benchmark)则是专门针对中文文本向量的评测基准,被认为是目前业界最全面、最权威的中文语义向量评测基准之一,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。
对于国内开发者而言,我们更加会专注C-MTEB。
C-MTEB榜单
我们知道了评测的基准,但是如果每一个模型我们都去测评一下,岂不是非常耗时耗力。这就不得不给大家介绍MTEB榜单了。
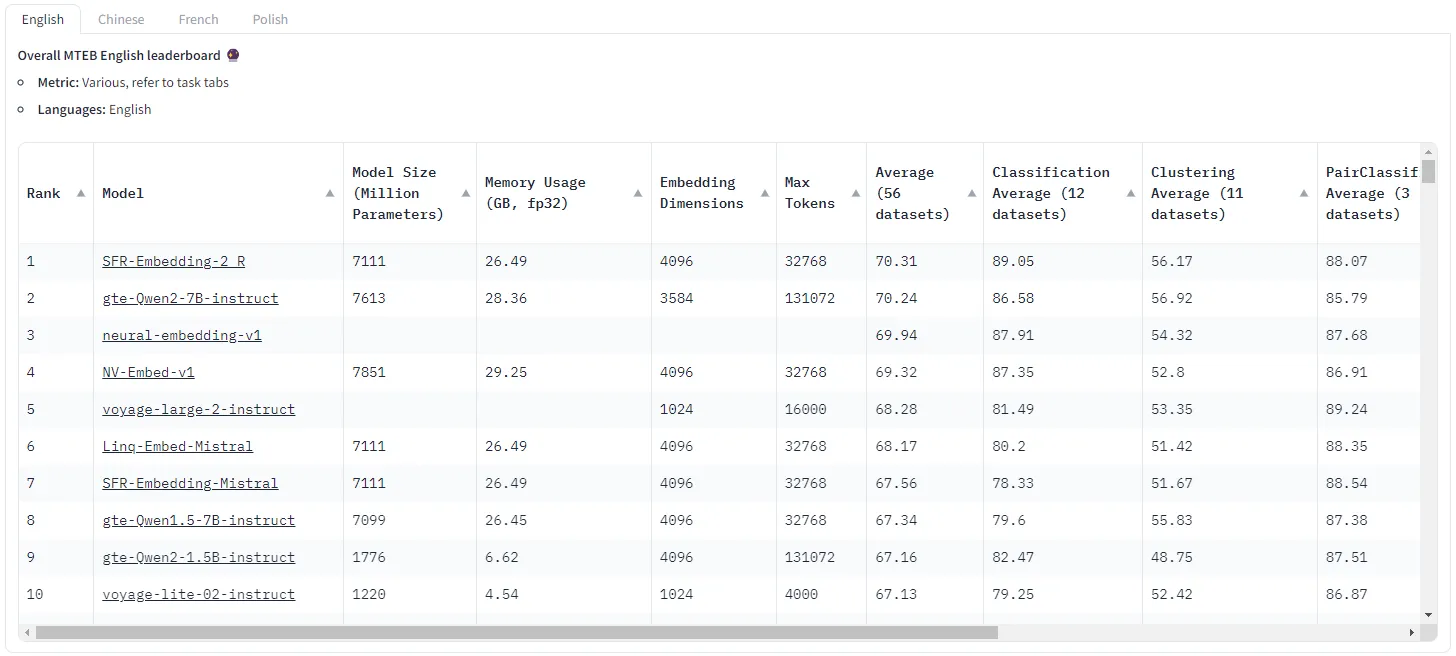
通过榜单我们就可以很容易地看到模型的综合排名以及在各分类任务上的得分。
- Rank 排名
- Model 模型
- Model Size 模型大小(参数量)
- Memory Usage 占用空间
- Embedding Dimensions 维度数
- Max Tokens 最大tokens数
- Average(56 datasets) 在56个数据集上的平均得分
- Classification Average (12 datasets) 分类
- Clustering Average (11 datasets) 聚类
- PairClassification Average (3 datasets) 判别
- Reranking Average (4 datasets) 排序
- Retrieval Average (15 datasets) 检索
- STS Average (10 datasets) 语义文本相似度
- Summarization Average (1 datasets) 总结
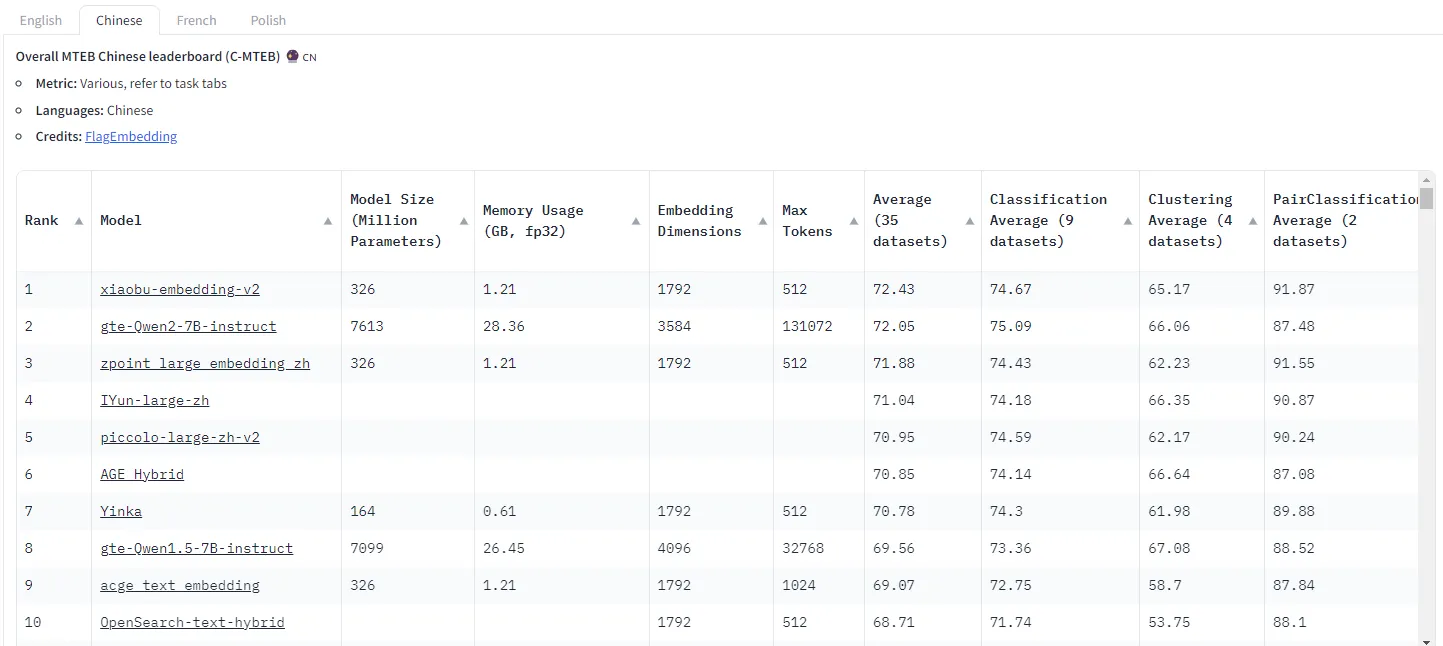
最后,我们来看一下C-MTEB的前十名吧
进阶
MTEB可以帮助我们更加科学地评估大模型的效果,而MTEB榜单则让我们选择大模型变得更容易。如果你也关心MTEB榜单,可以关注:遇码,回复mteb获取榜单地址。