RAG必备:手把手教你使用Attu管理高性能开源免费向量数据库——Milvus
前面已经讲解了Milvus的部署,本文则重点讲解Milvus可视化管理工具Attu的使用。
登录
访问http://localhost:8000,如果没有登录则会跳转到登录页面。
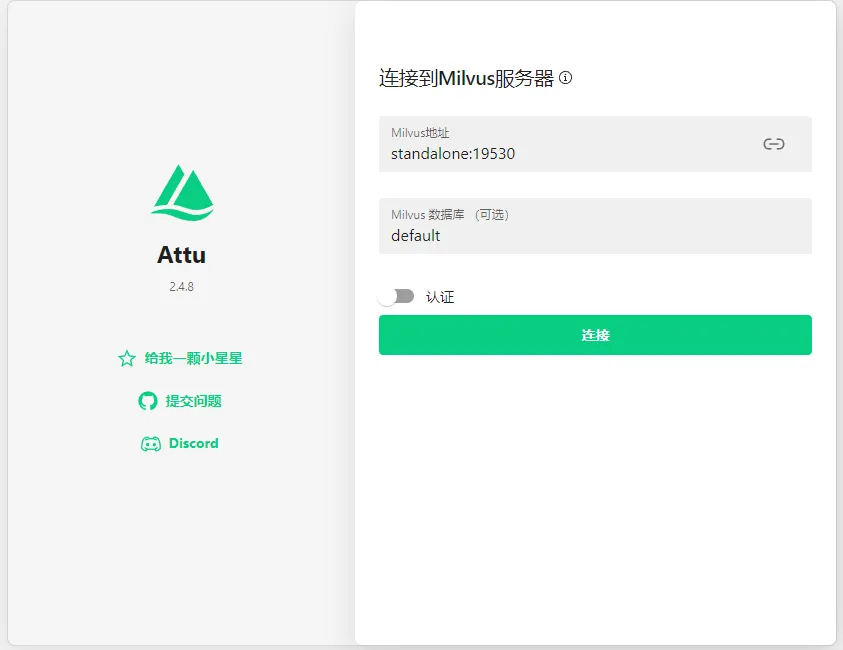
Milvus地址和Milvus数据库无需修改,直接点击连接。
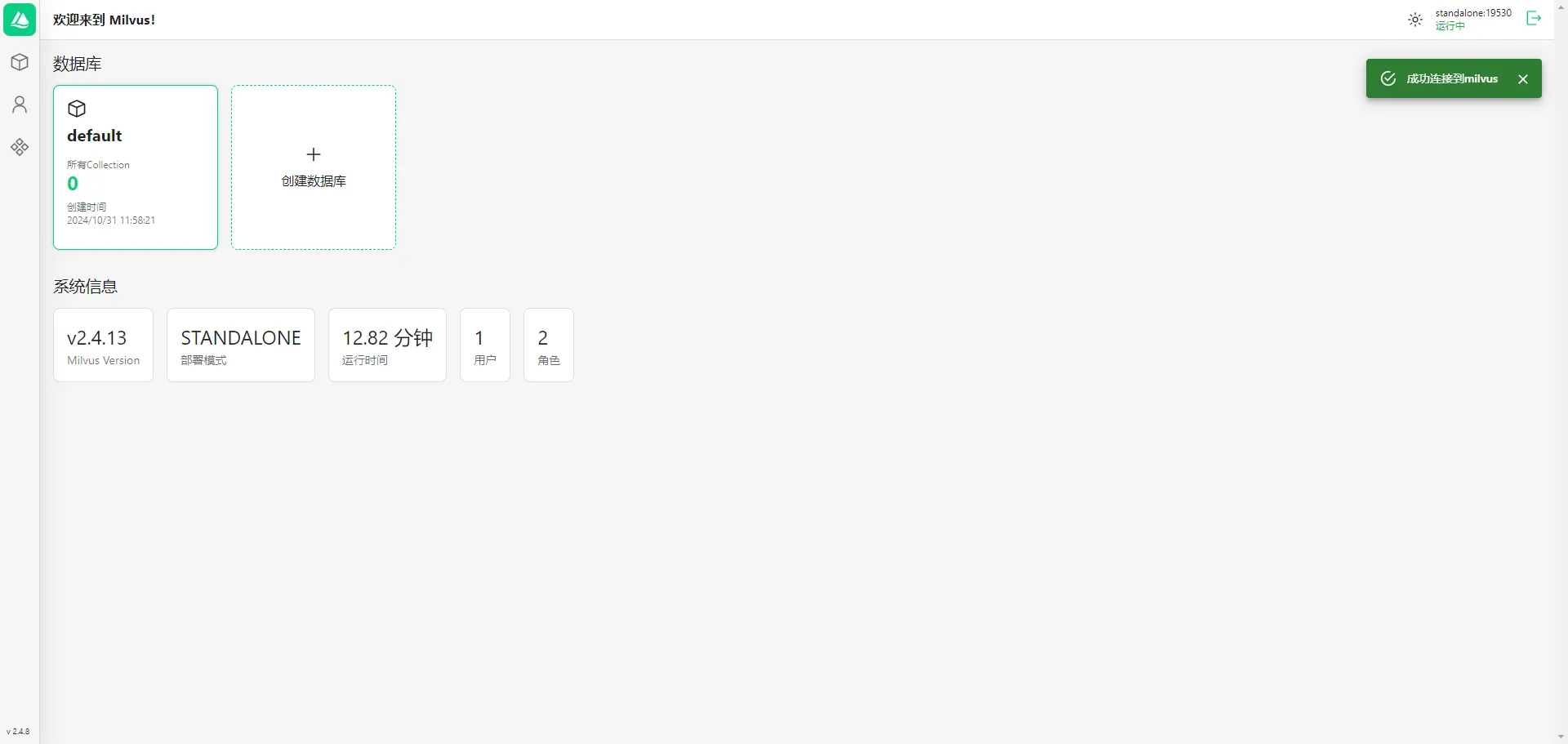
欢迎页
欢迎页包含两部分:数据库和系统信息。
- 数据库
默认展示了default默认数据库,以及所包含的Collection数量。同时支持用户创建数据库。
- 系统信息
可以查看Milvus的版本、部署模式、运行时间、用户数和角色数。
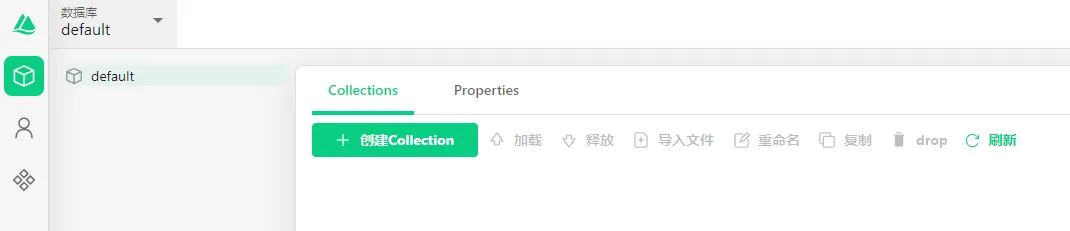
数据库
左侧可以切换所创建的数据库,以及查看数据库中已经创建的Collections列表。一个Collection我们可以理解为一张数据表。
同时可以完成Colletion管理和属性的配置。

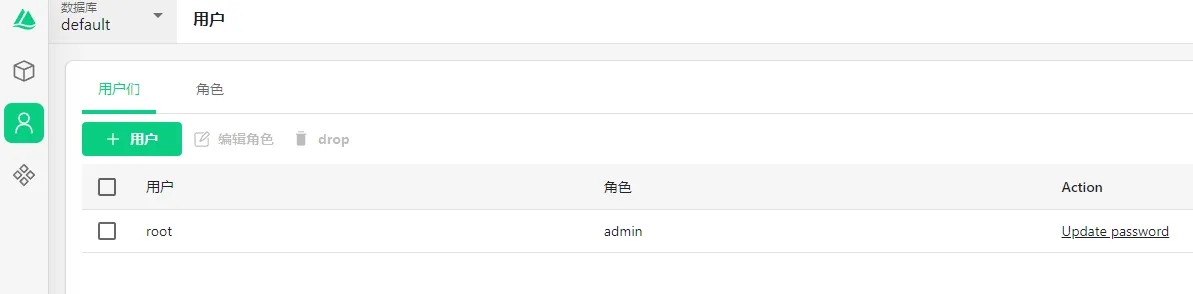
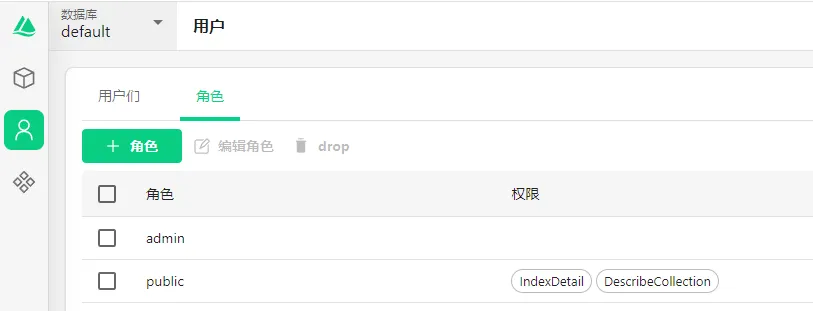
用户
Attu提供了精细化的用户和权限管理。
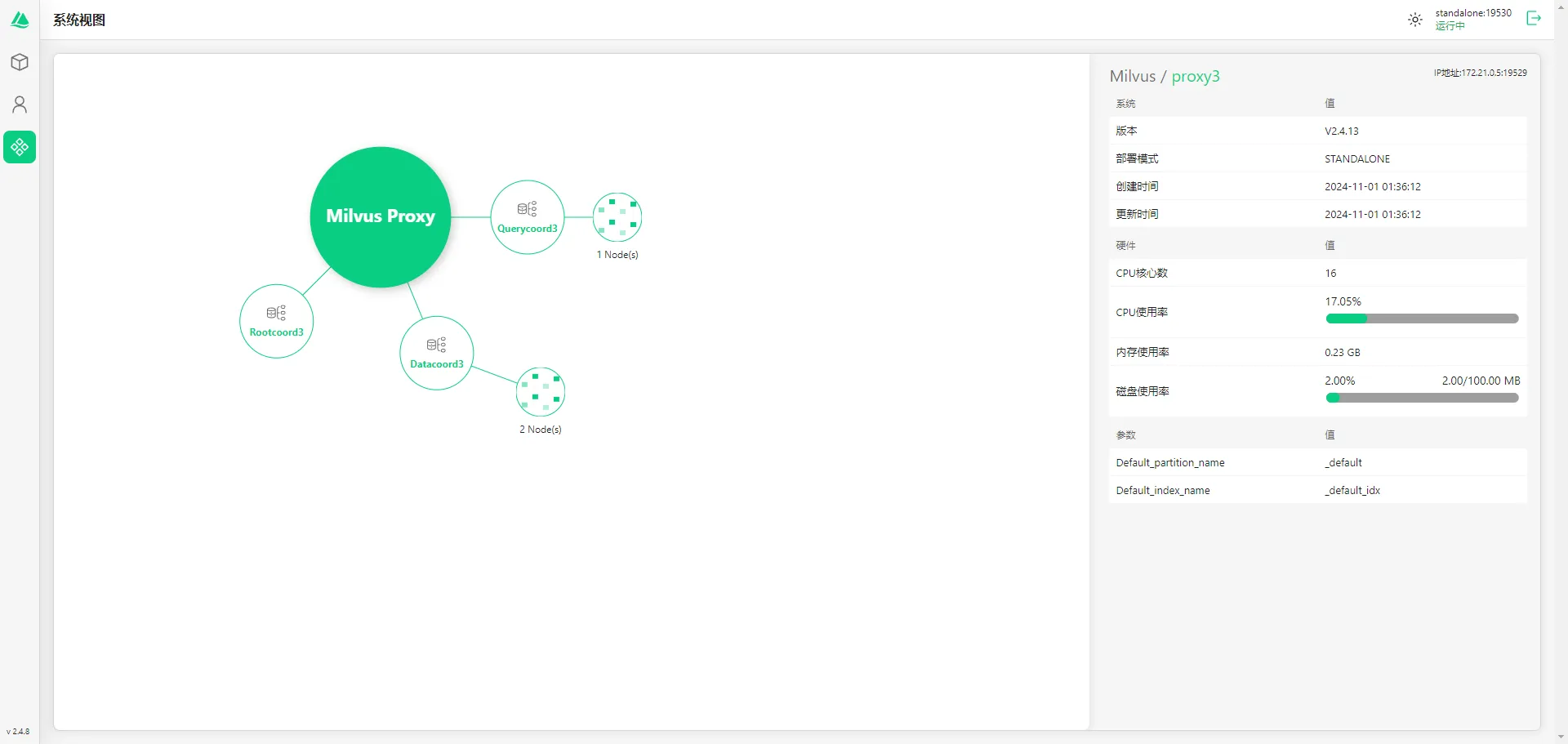
系统视图
通过系统视图我们可以清晰地查看各个服务节点的信息和资源使用情况。
了解了Attu的功能模块,相信你已经跃跃欲试了。下面将手把手通过一个案例为大家详细讲解Milvus。
使用Milvus
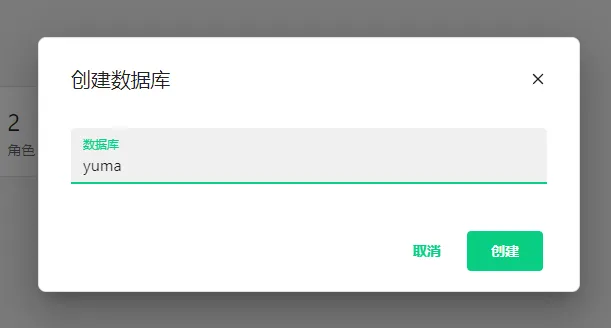
- 在欢迎页创建数据库
yuma
- 在数据库页选择数据库
yuma
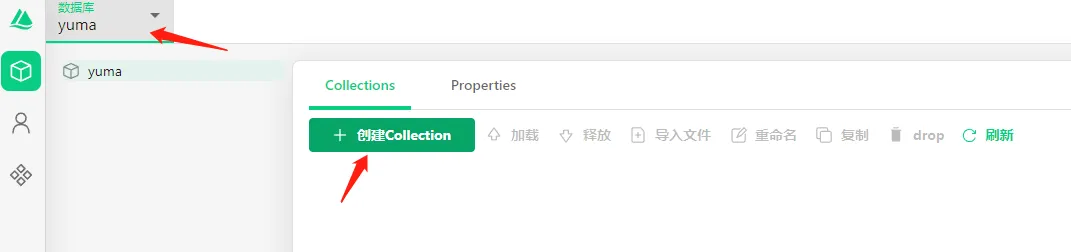
- 创建名为
news的Colletion
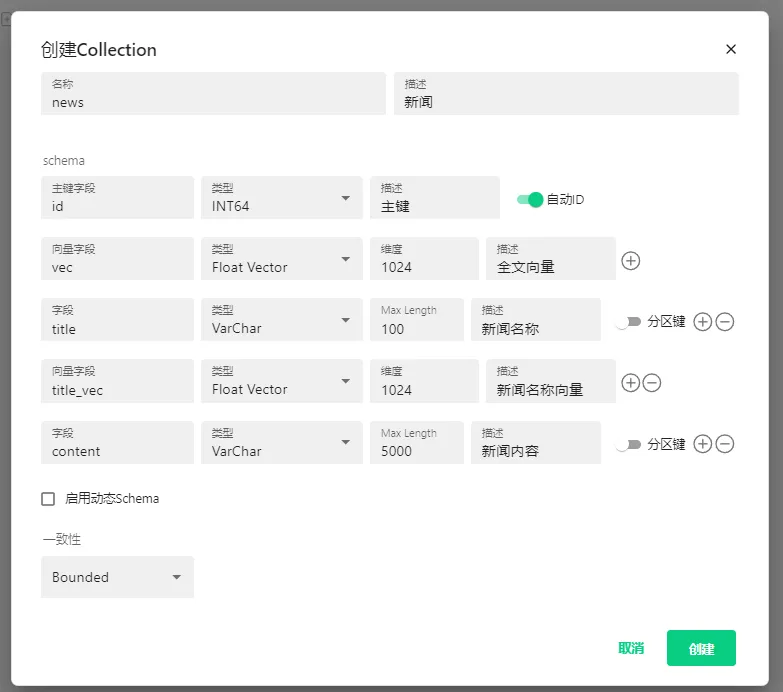
主键字段开启自动ID后,在写入数据的时候,用户无需提供id列值,数据库会自动帮用户生成,类似于Mysql的自增ID。
一个Collection中至少要包含一个向量字段(向量场),如vec,我们定义维度值为1024。向量字段类型有:
Binary Vector
将二进制数据存储为 0 和 1 的序列,用于图像处理和信息检索中的紧凑特征表示。
Float Vector
存储 32 位浮点数,常用于科学计算和机器学习中的实数表示。
Float16 Vector
存储 16 位半精度浮点数,用于深度学习和 GPU 计算,以提高内存和带宽效率。
BFloat16 Vector
存储精度降低但指数范围与 Float32 相同的 16 位浮点数,在深度学习中很受欢迎,可在不明显影响精度的情况下降低内存和计算要求。
Sparse Vector
存储非零元素及其相应索引的列表,用于表示稀疏向量。
启用动态Schema则表示用户不需要提前创建所有字段,可以在使用过程中创建新字段。
创建好以后,我们发现该Collection的状态处于未加载,表示此时还无法使用。 
- 创建索引
用户可以为任意非向量字段创建索引,即所有向量列必须创建索引。 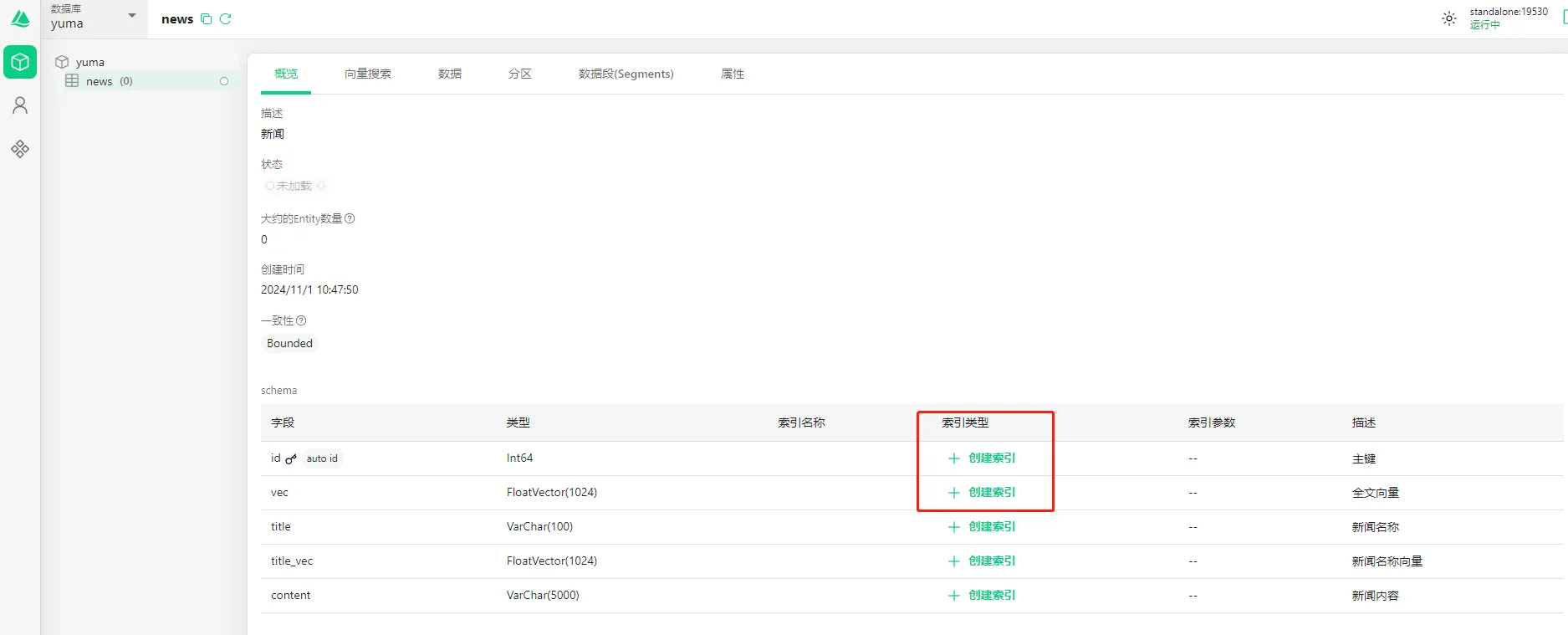
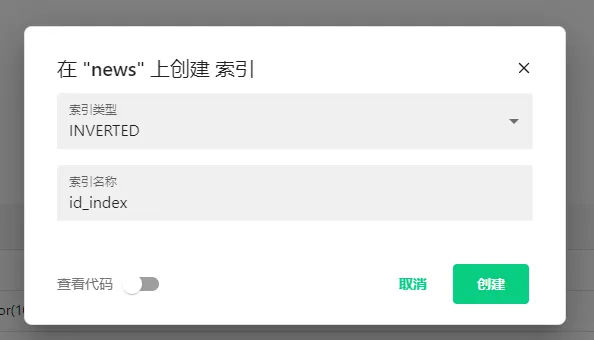
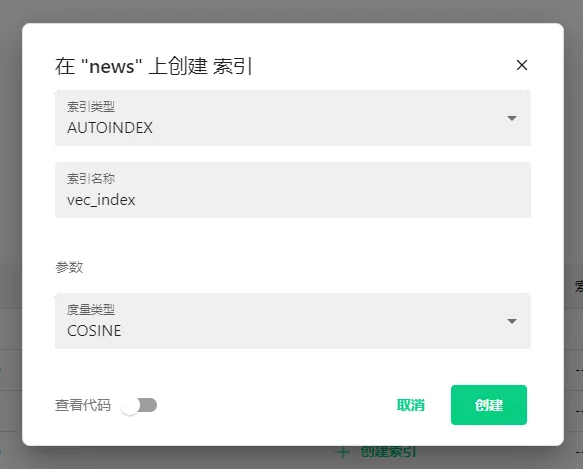
为所有向量字段创建好索引后,Collection的状态未加载就可以点击了。 
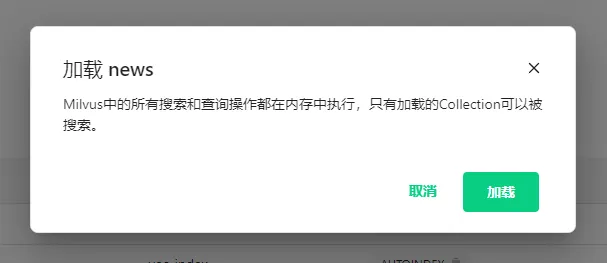
加载完成后状态变为已加载,表示该Collection可以使用了。 
- 向量搜索
此时我们就可以使用向量搜索了 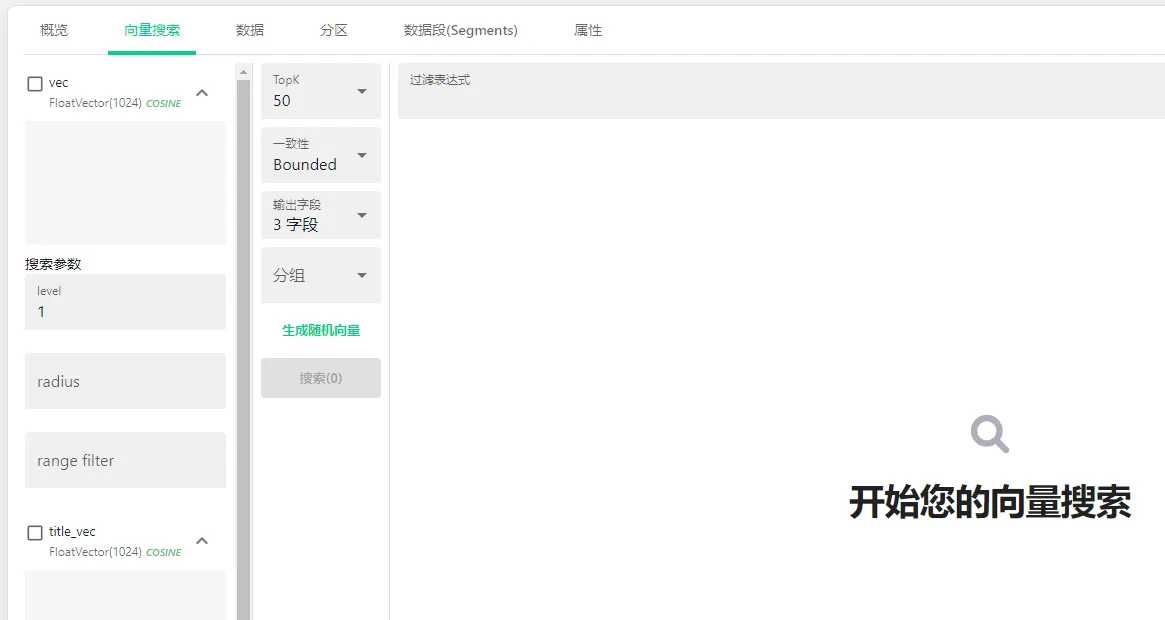
也可以在数据下查看或查询数据 
至此,想必你已经对Milvus有了一个真真切切的认识,它不再是一个只停留在想象层面的一个概念。
进阶
如何才能把自己的数据写入到Milvus中呢?如何才能搜索到符合条件的数据呢?接下来我们会介绍如何用Python实现数据写入Milvus。如果你想进一步学习Milvus,可以关注:遇码,回复milvus获取官方文档。